Tus Datos Están Desordenados: ¿Qué Arreglar Antes de Pensar en IA?
Antes de gastar en IA, arregla tus datos. Los 4 problemas que bloquean cualquier implementación y un checklist de preparación para decisores.
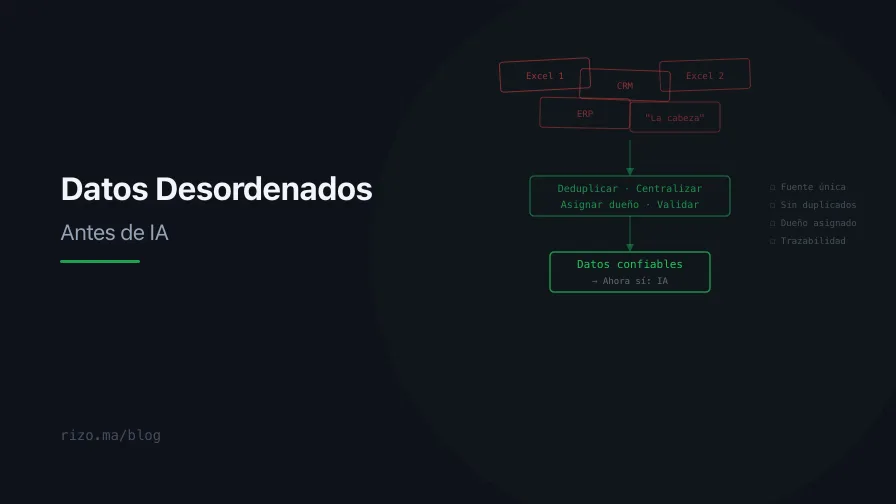
Cada semana llega un ejecutivo con la misma pregunta: “¿Cómo implementamos inteligencia artificial?” La pregunta es legítima. La presión del mercado, la competencia, los proveedores de tecnología, los titulares de prensa — todo apunta en la misma dirección. Pero la respuesta honesta, la que rara vez quieren escuchar, es casi siempre la misma: todavía no. No porque la IA no funcione. Funciona. No porque no sea relevante para su negocio. Probablemente lo es. Sino porque antes de implementar IA, se necesitan datos que sean consistentes, accesibles y confiables. Y en la mayoría de las empresas medianas de la región, esos datos no existen en esa condición.
No es un problema de tecnología. Es un problema de gestión. Según la investigación de Thomas Redman publicada en Harvard Business Review (2017), solo el 3% de los datos de las organizaciones evaluadas cumplían con estándares básicos de calidad. El 47% de los registros nuevos contenían al menos un error crítico. Estas cifras no son de empresas descuidadas o atrasadas tecnológicamente. Son promedios de organizaciones de todos los tamaños y sectores. Si eso ocurre en empresas con departamentos de TI de 50 personas y presupuestos de datos dedicados, la situación en una empresa de 150 empleados en Panamá o Costa Rica, donde “datos” significa Excel compartidos por correo, no es difícil de imaginar.
Este artículo documenta los cuatro problemas de datos que bloquean cualquier implementación de IA, propone un checklist de preparación que cualquier decisor puede aplicar en una hora, y establece un orden pragmático de prioridades para arreglar lo que se puede arreglar antes de gastar un dólar en inteligencia artificial. Como desarrollamos en detalle en la guía realista de IA para empresas medianas, más del 80% de los proyectos de IA fracasan según investigación de RAND Corporation (Ryseff, De Bruhl y Newberry, 2024), y la causa rara vez es la tecnología. La causa es lo que alimenta a la tecnología: los datos.
El estado real de los datos en empresas de 50-500 personas
En Rizoma trabajamos con organizaciones de 50 a 500 personas en Panamá y Centroamérica. Empresas de servicios, manufactura, distribución, servicios financieros, salud. Hay patrones que se repiten con una consistencia que debería preocupar a cualquier comité de dirección que esté considerando una inversión en IA.
El CRM tiene entre un 10% y un 30% de registros duplicados o incompletos. Esto no es una estimación arbitraria: según datos del sector de gestión de datos, las empresas sin programas activos de calidad de datos experimentan tasas de duplicación de entre el 10% y el 30% de sus bases (Plauti, 2021). En la práctica, esto significa que la empresa no sabe con certeza cuántos clientes activos tiene. No puede segmentar con confianza. No puede medir retención real. Cualquier modelo de IA que se alimente de esos datos va a producir resultados que se ven sofisticados pero que están construidos sobre arena.
Los reportes mensuales se construyen manualmente. El analista financiero pasa tres días al mes consolidando datos de cuatro sistemas diferentes, cruzando en Excel, corrigiendo inconsistencias, y produciendo un PowerPoint que llega al comité ejecutivo una semana después del cierre. Para cuando la información llega al decisor, tiene entre 10 y 15 días de antigüedad. No es información para decidir; es historia reciente presentada como gestión.
Cada departamento tiene su propia versión de la verdad. Ventas reporta 420 clientes activos. Operaciones reporta 380. Finanzas reporta 395. Los tres tienen razón según su propia definición de “cliente activo,” y los tres están produciendo decisiones basadas en una realidad parcial. Cuando no existe una definición única y compartida de los conceptos centrales del negocio, no hay base sobre la cual construir análisis confiable — ni con IA ni sin ella.
El conocimiento crítico vive en la cabeza de dos o tres personas. El gerente de operaciones que lleva 12 años sabe qué proveedor responde más rápido, qué cliente tiene condiciones especiales no documentadas, qué proceso tiene una excepción que nunca se formalizó. Cuando esa persona se va de vacaciones, el área funciona a media máquina. Cuando renuncia, el área pierde capacidad que tomará meses reconstruir. Ese conocimiento tácito no está en ningún sistema, no se puede consultar, y por lo tanto no existe para ninguna herramienta de IA.
IBM estimó en 2016 que el costo de la mala calidad de datos para la economía estadounidense alcanzaba los 3.1 billones de dólares anuales (Redman, 2016). Gartner ha reportado que las organizaciones pierden un promedio de 12.9 millones de dólares anuales por problemas de calidad de datos. Estas cifras corresponden a economías desarrolladas con infraestructura de datos más madura que la nuestra. Proporcionalmente, el impacto en una empresa mediana centroamericana no es menor; simplemente no se mide, y lo que no se mide no se gestiona.
La evidencia disponible sugiere que hasta el 50% del tiempo de los trabajadores del conocimiento se desperdicia buscando datos, identificando y corrigiendo errores, y buscando fuentes confirmatorias para datos en los que no confían (Redman, 2008). En una empresa de 200 personas donde 60 son trabajadores del conocimiento, eso equivale a 30 personas-hora desperdiciadas por día. No es un problema de eficiencia marginal. Es una hemorragia estructural que la organización ha normalizado.
Los 4 problemas de datos que bloquean cualquier implementación de IA
Los problemas de datos no son todos iguales. Algunos son visibles y relativamente simples de corregir. Otros son estructurales y requieren cambios en la forma en que la organización opera. La siguiente taxonomía no es exhaustiva, pero cubre los cuatro patrones que, en nuestra experiencia, aparecen con mayor frecuencia y tienen mayor impacto sobre la viabilidad de cualquier proyecto de IA.
Datos duplicados e inconsistentes
Es el problema más visible y, paradójicamente, uno de los más tolerados. El mismo cliente aparece en el sistema con tres nombres diferentes: “Constructora ABC, S.A.”, “CONST. ABC” y “ABC Constructora.” Cada registro tiene información parcial distinta. El vendedor A tiene el teléfono actualizado en uno, el vendedor B tiene la dirección correcta en otro, y contabilidad tiene el RUC correcto en un tercero. Ningún registro individual tiene la información completa y correcta.
Las consecuencias operativas son concretas. La empresa envía tres cotizaciones al mismo cliente desde tres vendedores diferentes. El reporte de ventas cuenta tres clientes donde hay uno. El modelo de segmentación — si alguna vez se intenta — produce clusters contaminados. Un sistema de recomendación entrenado con estos datos no recomienda; confunde.
La raíz del problema no es técnica. Es de proceso. No existe una regla de negocio que defina cómo se escribe el nombre de un cliente. No hay validación al momento de la captura. No hay proceso periódico de deduplicación. Y cuando alguien sugiere limpiar la base, la respuesta típica es: “no tenemos tiempo para eso ahora.” El “ahora” lleva años.
La corrección requiere tres acciones: definir un estándar de captura (cómo se escribe un nombre, qué campos son obligatorios, qué formato tiene cada dato), implementar validación en el punto de entrada (el sistema no permite guardar un registro sin los campos mínimos), y ejecutar una limpieza inicial de la base existente. Ninguna de estas acciones requiere IA. Requieren decisión y disciplina.
Datos atrapados en silos
Cada sistema es una isla. El ERP tiene los datos financieros. El CRM tiene los datos comerciales. El sistema de nómina tiene los datos de talento humano. El sistema de producción tiene los datos operativos. Excel tiene todo lo demás. Ninguno habla con los otros, o cuando lo hacen, lo hacen mediante procesos manuales de exportación e importación que introducen latencia, errores de transformación y versiones desincronizadas.
El impacto de los silos de datos va más allá de la ineficiencia operativa. Los silos impiden preguntas que cruzan dominios. ¿Cuál es la rentabilidad real por cliente cuando se incluyen costos de servicio postventa? No se puede calcular porque ventas y servicio están en sistemas separados. ¿Qué relación hay entre la rotación de personal en el área comercial y la caída en el índice de satisfacción del cliente? No se puede analizar porque RRHH y servicio al cliente no comparten datos.
La IA, por definición, funciona mejor cuanto más datos conectados tiene. Un modelo que solo ve datos de un silo produce insights de un silo — parciales, incompletos, potencialmente engañosos. La promesa de la IA de encontrar patrones que los humanos no ven requiere que esos patrones existan en datos que el modelo pueda ver. Si los datos relevantes están en cinco sistemas que no se comunican, el modelo no va a encontrar nada que un analista con acceso a Excel no pudiera encontrar manualmente.
La solución no es necesariamente un data warehouse de varios millones de dólares. Para una empresa de 200 personas, puede ser tan simple como una capa de integración que sincronice los datos maestros (clientes, productos, empleados) entre los sistemas principales. Puede ser un dashboard unificado que consulte múltiples fuentes. Puede ser, en el caso más básico, una convención sobre qué sistema es la “fuente de verdad” para cada tipo de dato, documentada y respetada. Como desarrollamos en el artículo sobre gobierno de datos sin parálisis, el primer paso no es la herramienta tecnológica sino la decisión organizacional sobre quién decide qué cuando dos sistemas discrepan.
Datos sin dueño
Este es posiblemente el problema más dañino y el más difícil de resolver, porque no es técnico sino organizacional. Nadie es responsable de la calidad de los datos. Todo el mundo asume que “alguien” se encarga. TI asume que el negocio es dueño de la calidad semántica de los datos. El negocio asume que TI es responsable de que los sistemas funcionen correctamente. El resultado es una zona gris donde los errores se acumulan sin que nadie tenga el mandato ni los incentivos para corregirlos.
Ladley (2019) documentó este patrón como uno de los más prevalentes en organizaciones que intentan implementar gobierno de datos: la confusión entre la responsabilidad técnica (que los sistemas funcionen) y la responsabilidad de negocio (que los datos signifiquen lo que deben significar y tengan la calidad necesaria para la decisión que soportan). Un campo de “estado del cliente” que tiene valores como “activo”, “Activo”, “A”, “vigente” y en blanco no es un problema técnico. El sistema permite guardar cualquier texto. Es un problema de negocio: nadie definió los valores válidos, nadie los implementó como restricción, y nadie revisa periódicamente si se cumplen.
El concepto de “data steward” o custodio de datos que la literatura propone como solución tiene mérito pero requiere adaptación al contexto de empresas medianas. No se necesita un cargo de tiempo completo dedicado a la calidad de datos. Se necesita que para cada dominio de datos crítico (clientes, productos, finanzas, operaciones) haya una persona identificada que tenga la autoridad para definir estándares y la responsabilidad de verificar que se cumplan. Puede ser el gerente comercial para datos de clientes. Puede ser el controller para datos financieros. Lo que no puede ser es nadie.
Cuando nadie es dueño de los datos, nadie los defiende. Y datos sin defensa se degradan. La entropía de datos — la tendencia natural de la calidad a deteriorarse con el tiempo si no hay mantenimiento activo — es un fenómeno documentado que afecta a toda organización. Redman (2008) estimó que sin intervención, la calidad de una base de datos se degrada entre un 2% y un 5% mensual. En un año sin mantenimiento, una base que empezó con 90% de calidad puede terminar debajo del 60%.
Datos sin historia
El último patrón es particularmente relevante para IA porque la mayoría de los modelos útiles para empresas medianas — predicción de demanda, análisis de tendencias, detección de anomalías — requieren datos históricos. Y muchas organizaciones no los tienen. No porque no los hayan generado, sino porque los sobrescribieron.
El ejemplo más común: el sistema actualiza el precio del producto directamente, sin guardar el precio anterior ni la fecha del cambio. Cuando alguien pregunta “¿cuánto costaba este producto hace 6 meses?” la respuesta es “no sé, habría que buscar en las facturas.” El sistema de RRHH actualiza el salario del empleado sin mantener un registro del salario anterior. El CRM cambia el estado del cliente de “activo” a “inactivo” sin registrar cuándo ocurrió el cambio ni por qué.
La ausencia de datos históricos no es solo un problema para la IA. Es un problema para la gestión. Sin historia, no hay tendencias. Sin tendencias, no hay predicción. Sin predicción, toda decisión es reactiva. La organización opera en un presente perpetuo donde cada análisis empieza desde cero porque no hay línea base con la cual comparar.
La corrección es conceptualmente simple pero requiere cambios en la arquitectura de datos: pasar de modelos que sobrescriben a modelos que versionan. En términos prácticos, esto puede significar agregar campos de fecha de modificación y usuario que modificó en las tablas críticas, implementar tablas de auditoría que registren los cambios, o configurar los sistemas para que mantengan historial en lugar de sobrescribir. Ninguna de estas acciones es compleja técnicamente. Pero requieren la decisión explícita de que la historia de los datos tiene valor — una decisión que muchas organizaciones no han tomado porque nadie la ha planteado.
Checklist de preparación: ¿estás listo para IA?
Antes de evaluar proveedores de IA, antes de aprobar un presupuesto de implementación, antes de asignar un equipo al proyecto, responde estas diez preguntas. Cada respuesta afirmativa vale un punto. La puntuación indica el nivel de preparación real de la organización — no el nivel de entusiasmo ni el de presión del mercado.
| # | Pregunta | Sí / No |
|---|---|---|
| 1 | ¿Puedes generar un reporte de ventas trimestral en menos de 1 hora sin llamar a nadie? | |
| 2 | ¿Sabes cuántos clientes activos tienes con una certeza de ±5%? | |
| 3 | ¿Existe una definición documentada y compartida de “cliente activo” que todas las áreas usan? | |
| 4 | ¿Hay una persona identificada como responsable de la calidad de los datos de clientes? | |
| 5 | ¿Tus sistemas principales (ERP, CRM, nómina) comparten al menos un identificador común para las entidades clave? | |
| 6 | ¿Puedes consultar datos históricos de precios, costos o estados de hace 12 meses directamente en el sistema? | |
| 7 | ¿El proceso de captura de datos tiene validaciones que impidan guardar registros incompletos o con formato incorrecto? | |
| 8 | ¿Los reportes que llegan al comité ejecutivo se generan desde una fuente única, sin consolidación manual en Excel? | |
| 9 | ¿Si el analista principal de datos renuncia mañana, alguien más puede generar los reportes críticos en menos de una semana? | |
| 10 | ¿Tienes documentados los 5 indicadores más importantes del negocio con su definición, fuente de datos y frecuencia de actualización? |
Interpretación:
| Puntaje | Diagnóstico | Recomendación |
|---|---|---|
| 8-10 | La organización tiene fundamentos de datos sólidos | Puede evaluar casos de uso de IA con probabilidad razonable de éxito |
| 5-7 | Hay capacidades parciales pero brechas significativas | Priorizar las brechas identificadas antes de iniciar proyectos de IA |
| 3-4 | La infraestructura de datos es insuficiente | Invertir en fundamentos de datos; la IA amplificará los problemas existentes |
| 0-2 | La organización opera sin gestión de datos | Cualquier inversión en IA será dinero perdido; empezar por lo básico |
La experiencia indica que la mayoría de las empresas de 50 a 500 personas en la región puntúan entre 2 y 4. Esto no es un juicio de valor ni una crítica. Es un diagnóstico. Las organizaciones que reconocen dónde están pueden planificar un camino realista. Las que se mienten a sí mismas terminan invirtiendo en IA que no funciona y concluyendo que “la IA no sirve para nuestro tipo de negocio” — cuando el problema nunca fue la IA.
Si tu puntuación está debajo de 5, la IA no es tu próximo paso. La IA será tu paso siguiente después de corregir los fundamentos. Y la buena noticia es que corregir los fundamentos no requiere años ni millones de dólares. Requiere secuencia, disciplina y alguien con autoridad para tomar decisiones sobre datos.
¿Qué arreglar primero (y qué puede esperar)?
La tentación ante un diagnóstico desfavorable es querer arreglar todo al mismo tiempo. Un proyecto de “transformación de datos” de 18 meses con un alcance ambicioso que incluye data warehouse, catálogo de datos, políticas de gobierno, herramientas de calidad y capacitación transversal. La evidencia sobre este tipo de proyectos es desalentadora: la mayoría se estanca en el mes 4, cuando la urgencia del día a día se come los recursos asignados al proyecto y el patrocinio ejecutivo se diluye porque los resultados tangibles tardan en llegar.
La alternativa es una secuencia pragmática de intervenciones cortas con resultados visibles. Lo que sigue es un plan de 90 días que hemos visto funcionar en organizaciones de este tamaño, ajustable según el contexto específico de cada empresa.
Semanas 1-2: Definir la fuente única de verdad para datos de clientes.
El dato de cliente es el más transversal, el más usado y el más contaminado en la mayoría de las organizaciones. El primer paso es decidir qué sistema es la fuente de verdad para los datos maestros de clientes: nombre, identificación fiscal, dirección, contacto, estado. Típicamente es el CRM, pero puede ser el ERP si la operación está centrada en facturación. Lo importante no es cuál sistema se elige sino que la decisión se tome, se documente y se comunique. A partir de ese momento, cualquier discrepancia entre sistemas se resuelve consultando la fuente de verdad.
Semanas 3-4: Eliminar la doble captura de datos.
Identificar los puntos donde la misma información se captura en más de un sistema manualmente. El vendedor registra el pedido en el CRM y luego alguien lo vuelve a capturar en el ERP. El analista de RRHH registra una contratación en el sistema de nómina y luego actualiza manualmente un Excel de headcount. Cada punto de doble captura es una fuente de inconsistencia y un desperdicio de tiempo. La solución puede ser una integración técnica (API entre sistemas), una automatización simple (macro, script, herramienta de bajo código), o una eliminación del paso redundante. En esta etapa no se busca la solución perfecta; se busca eliminar las fuentes más evidentes de error.
Mes 2: Documentar las 3 consultas y reportes más críticos del negocio.
Para cada uno, documentar: qué pregunta de negocio responde, de qué sistemas obtiene los datos, qué transformaciones manuales se aplican, quién lo produce, cuánto tiempo toma, y con qué frecuencia se genera. Esta documentación tiene dos propósitos. Primero, hace visible el costo real de la falta de integración de datos. Segundo, establece los candidatos naturales para automatización: si un reporte toma 3 días de trabajo manual cada mes, automatizarlo libera 36 días-persona al año — un retorno de inversión que cualquier gerente entiende sin necesidad de explicar qué es machine learning.
Meses 2-3: Asignar un responsable de calidad de datos por área crítica.
No es un cargo nuevo. Es una responsabilidad adicional asignada a alguien que ya trabaja con esos datos y tiene contexto de negocio. El responsable de calidad de datos de clientes puede ser el gerente comercial. El de datos financieros, el controller. El de datos de operaciones, el gerente de producción o logística. Lo que cada responsable necesita es claro: una definición de los campos críticos de su dominio, una regla de calidad para cada campo (formato, completitud, validez), y una cadencia de revisión (mensual es suficiente para empezar). Como desarrollamos en el artículo sobre automatización inteligente vs automatización ciega, automatizar sin fundamentos solo acelera los errores.
Mes 3: Establecer un proceso mínimo de historialización.
Para los datos más críticos del negocio — precios, estados de clientes, condiciones comerciales, indicadores clave — configurar los sistemas para que registren fecha de cambio y valor anterior. Si el sistema no lo soporta nativamente, una tabla de auditoría simple cumple la función. El objetivo no es construir un data lake. Es garantizar que dentro de 12 meses, la organización tenga al menos un año de datos históricos limpios sobre los cuales un modelo de IA pueda trabajar.
Este plan de 90 días no resuelve todos los problemas de datos de la organización. No pretende hacerlo. Lo que sí hace es establecer los fundamentos mínimos sobre los cuales una implementación de IA tiene probabilidad de éxito. Sin estos fundamentos, la IA no tiene sobre qué operar.
¿Cuándo sí estás listo para IA?
Después de la sección anterior, sería fácil concluir que “nunca estamos listos” y posponer la IA indefinidamente. Ese no es el mensaje. El mensaje es que la preparación tiene un umbral mínimo, y cruzar ese umbral es alcanzable en meses, no en años. La pregunta no es si la organización está perfecta — ninguna lo está — sino si tiene las condiciones mínimas para que un proyecto de IA específico tenga probabilidad razonable de producir valor.
Las señales de preparación mínima son tres.
Primera: datos centralizados para al menos un dominio. No se necesita que toda la organización esté integrada. Se necesita que el dominio de datos relevante para el caso de uso de IA esté centralizado. Si la IA va a trabajar con datos de clientes, los datos de clientes deben estar en una fuente confiable. Si va a trabajar con datos operativos, esos son los que necesitan estar limpios. La preparación es específica al caso de uso, no genérica.
Segunda: capacidad de responder preguntas básicas de negocio sin compilación manual. Si el equipo puede generar un reporte de las métricas clave del dominio relevante en menos de una hora, usando datos de sistemas (no Excel manuales), la base operativa existe. Si generar ese reporte requiere tres días de trabajo manual, la IA no tiene una base funcional sobre la cual operar. La evidencia disponible sugiere que las organizaciones con esta capacidad tienen tasas de éxito significativamente mayores en proyectos de IA que aquellas que no la tienen.
Tercera: alguien responsable de la calidad de los datos. No un comité. No un documento de política. Una persona con nombre y apellido que sabe qué datos están bajo su custodia, qué estándares de calidad deben cumplir, y qué hacer cuando no los cumplen. Sin esta persona, los datos se degradan, el modelo de IA se entrena con basura creciente, y los resultados se deterioran silenciosamente hasta que alguien se da cuenta de que las predicciones dejaron de tener sentido hace tres meses.
Cuando estas tres condiciones se cumplen — datos centralizados en un dominio, capacidad de consulta operativa, responsable identificado — la organización puede evaluar un caso de uso de IA con fundamento. No todos los casos de uso. Uno. El más acotado, el más cercano a datos que ya existen, el que tiene el mayor potencial de retorno visible. Como argumentamos en el artículo sobre gobernanza de IA, la implementación sin gobernanza es experimentación con riesgo acumulado. Pero la gobernanza sin fundamento de datos es burocracia sin sustancia.
La secuencia correcta es: datos limpios, luego caso de uso definido, luego gobernanza proporcional, luego implementación acotada. No al revés. No todo al mismo tiempo.
El costo de no hacer nada
Hay un argumento implícito que algunas organizaciones usan para justificar la inacción: “hemos operado así durante años y funciona.” Es un argumento válido hasta que deja de serlo. La empresa que operaba con datos desordenados en 2015 competía contra otras empresas con datos igualmente desordenados. La empresa que opera con datos desordenados en 2026 compite contra organizaciones que están empezando a usar esos datos como ventaja competitiva. La brecha se amplía con cada trimestre que pasa.
Gartner reportó que el 59% de las organizaciones no mide la calidad de sus datos. Eso significa que la mayoría no sabe cuánto le está costando el desorden. No sabe cuántas horas se pierden en reconciliación manual. No sabe cuántos clientes reciben comunicaciones duplicadas o contradictorias. No sabe cuántas decisiones se toman con información incompleta o incorrecta. La ignorancia no es una estrategia; es un riesgo que crece con el tiempo.
El costo de arreglar los datos hoy es una fracción del costo de arreglarlos dentro de tres años, cuando el volumen es mayor, la deuda técnica se ha acumulado y la competencia ya está usando IA sobre datos limpios. La ventana de oportunidad para construir fundamentos sin presión competitiva inmediata se está cerrando. No se cerrará mañana. Pero se está cerrando.
Conclusión
La inteligencia artificial no arregla datos malos. Los amplifica. Un modelo de IA entrenado con datos duplicados produce recomendaciones duplicadas. Un modelo alimentado con datos incompletos produce predicciones incompletas. Un modelo que opera sobre silos produce insights fragmentados. La sofisticación del algoritmo no compensa la pobreza de los datos.
La pregunta que todo decisor debería hacerse antes de “¿cómo implementamos IA?” es “¿puedo confiar en mis datos para tomar una decisión importante?” Si la respuesta honesta es no, el camino está claro: arreglar los datos primero. No todos. No perfectamente. Los más críticos, para el caso de uso más valioso, en un plazo de 90 días. Eso es alcanzable. Eso es medible. Y eso es lo que separa a las organizaciones que eventualmente van a usar IA de forma efectiva de las que van a gastar dinero en tecnología que amplifica sus problemas.
Referencias
- IBM. (2016). The cost of poor data quality. IBM Big Data & Analytics Hub.
- Ladley, J. (2019). Data Governance: How to Design, Deploy, and Sustain an Effective Data Governance Program (2nd ed.). Academic Press.
- Plauti. (2021). Average rate of duplicates in CRM. Plauti Research.
- Redman, T. C. (2008). Data Driven: Profiting from Your Most Important Business Asset. Harvard Business Press.
- Redman, T. C. (2016). Bad data costs the U.S. $3 trillion per year. Harvard Business Review.
- Redman, T. C. (2017). Only 3% of companies’ data meets basic quality standards. Harvard Business Review.
- Ryseff, J., De Bruhl, B., & Newberry, S. J. (2024). The Root Causes of Failure for Artificial Intelligence Projects and How They Can Succeed. RAND Corporation.