IA para Empresas Medianas: ¿Qué Es Real, Qué Es Hype?
Solo el 23% de las implementaciones de IA en empresas medianas reportan éxito. La brecha no es tecnológica, es de criterio. Guía realista para decisores.
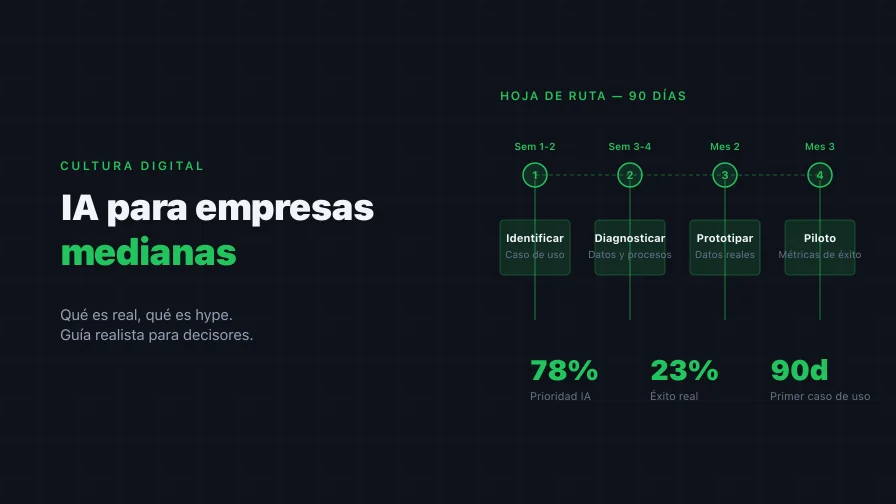
Según la encuesta global de McKinsey sobre el estado de la IA (2024), el 78% de los ejecutivos considera la inteligencia artificial una prioridad estratégica. Según el mismo estudio, el 65% de las organizaciones reporta uso regular de IA generativa, casi el doble que diez meses antes. Estas cifras proyectan una imagen de adopción acelerada y generalizada. Pero hay otro dato que rara vez aparece en las presentaciones de los proveedores de tecnología: según investigación de RAND Corporation (Ryseff, De Bruhl y Newberry, 2024), más del 80% de los proyectos de IA fracasan — el doble de la tasa de fracaso de proyectos de TI que no involucran IA. Un estudio del MIT (2025) encontró que el 95% de los pilotos de IA generativa en empresas no generan retorno medible.
Estos números no se contradicen. Lo que revelan es una brecha entre adopción y valor. Las organizaciones están comprando, probando, piloteando. Pero la mayoría no está obteniendo resultados que justifiquen la inversión. Y la brecha no es tecnológica. La tecnología funciona. La brecha es de criterio: saber qué problema resolver, con qué datos, bajo qué condiciones, y con qué nivel de preparación organizacional.
Este artículo está dirigido a decisores de empresas de 50 a 500 personas en Panamá y Centroamérica — el segmento donde la promesa de la IA es más grande y donde los errores de implementación son más costosos, porque no hay presupuesto para experimentos fallidos repetidos. No es un artículo motivacional. Es una guía de criterio basada en evidencia disponible, con casos de uso concretos, errores documentados y una hoja de ruta que se puede ejecutar en 90 días.
El estado real de adopción en empresas medianas en LATAM
La narrativa global sobre IA está dominada por lo que ocurre en empresas grandes. Las encuestas de McKinsey, MIT Sloan Management Review y BCG reportan tendencias agregadas donde el 70% de las organizaciones está piloteando o desplegando soluciones de IA. Pero cuando se desagrega por tamaño de empresa, la fotografía cambia sustancialmente. Según el informe de la OCDE sobre adopción de IA en pymes (2025), mientras el 52% de las empresas grandes en países miembros usa IA, solo el 20.4% de las empresas medianas (50-249 empleados) y el 11.9% de las pequeñas (10-49 empleados) lo hace. La brecha de adopción por tamaño es más pronunciada que la brecha por sector o por geografía.
En América Latina, la situación tiene particularidades propias. El Índice Latinoamericano de Inteligencia Artificial (ILIA 2025), publicado por la CEPAL y CENIA, documenta que la región concentra el 14% de las visitas globales a soluciones de IA — por encima de su participación en usuarios de internet. Pero la adopción se concentra en herramientas de consumo con bajos requerimientos técnicos. La región consume IA; no la adapta a sus contextos operativos en escala significativa. La adopción empresarial tuvo un incremento del 18% en 2024, alcanzando el 40% según datos regionales, pero este porcentaje incluye el uso de herramientas genéricas como ChatGPT para tareas individuales — no implementaciones que transformen procesos de negocio.
Un dato del ILIA 2025 que merece atención especial: solo el 17% de las empresas en la región ha establecido marcos claros de gobernanza para IA. Esto significa que la adopción está ocurriendo sin arquitectura de control, lo cual no solo es un riesgo regulatorio sino un indicador de que la implementación no tiene estructura — y sin estructura, no hay forma de medir ni de escalar. Como documentamos con datos de Panamá en Madurez de IA en Panamá, el nivel promedio de madurez es 2.3 sobre 5.0. La IA está presente en el discurso pero no integrada como palanca estratégica.
Para la empresa mediana en Centroamérica, el panorama real es este: la tecnología es accesible (modelos como servicio, plataformas de bajo código, APIs de IA generativa), pero las condiciones para que esa tecnología produzca valor — datos limpios, procesos documentados, capacidad interna de evaluación, patrocinio ejecutivo informado — están ausentes en la mayoría de las organizaciones. La OCDE reporta que el 50% de las pymes indica que sus empleados carecen de las competencias para usar IA generativa. No es un problema de acceso a la tecnología. Es un problema de preparación para usarla.
El error más frecuente que observamos en la región es empezar por la tecnología y buscar un problema que resolver con ella. La secuencia efectiva es la inversa: identificar un problema de negocio concreto, evaluar si la IA aporta algo que una solución más simple no pueda aportar, y solo entonces considerar la implementación. Davenport y Ronanki (2018), en su investigación publicada en Harvard Business Review con datos de 152 proyectos de IA, encontraron que las empresas obtienen mejores resultados con un enfoque incremental — empezando con automatización de procesos y análisis de datos — que con proyectos transformacionales ambiciosos. La empresa mediana que intenta replicar lo que hace una empresa del Fortune 500 con IA no está siendo ambiciosa; está siendo imprudente.
4 casos de uso con ROI demostrable para empresas de 50-500 personas
La pregunta “¿en qué debería usar IA?” es la pregunta equivocada. La pregunta correcta es: “¿dónde tengo un problema de negocio que involucra volumen, repetición y datos disponibles?” No todo problema se beneficia de IA. Los cuatro casos de uso que siguen comparten tres características: tienen ROI documentado en contextos similares al de empresas medianas, no requieren capacidades de ingeniería de ML interna, y pueden implementarse en semanas con herramientas disponibles en el mercado.
Automatización de procesos documentales
Toda empresa mediana produce y consume documentos: contratos, reportes, correspondencia, actas, propuestas, facturas. La evidencia disponible indica que el procesamiento manual de documentos toma entre 15 y 30 minutos por documento, mientras que el procesamiento asistido por IA reduce ese tiempo a segundos. Según datos del sector de procesamiento inteligente de documentos (IDP), las organizaciones que implementan automatización documental reportan una reducción del 50-70% en tiempos de ciclo de contratos y un ROI de 200-300% en el primer año, con períodos de retorno de inversión de 3 a 6 meses.
Para una empresa mediana, el caso de uso más inmediato no es el más sofisticado. Es la extracción de datos de documentos semi-estructurados: facturas de proveedores, contratos de clientes, reportes regulatorios. Las herramientas actuales de IDP (procesamiento inteligente de documentos) pueden extraer campos clave, clasificar documentos por tipo, y alimentar sistemas existentes sin requerir integración profunda. El departamento legal que revisa 200 contratos al mes puede reducir el tiempo de revisión inicial en un 60% — no eliminando la revisión humana sino automatizando la extracción y clasificación que precede al análisis.
El prerequisito es claro: los documentos deben existir en formato digital. Una empresa cuyo proceso contractual vive en carpetas físicas necesita digitalizar antes de automatizar. Esto suena obvio, pero en la práctica, un porcentaje significativo de las empresas medianas en la región mantiene procesos críticos en papel o en archivos no estructurados.
Análisis de datos operativos que ya existen pero nadie explota
La mayoría de las empresas medianas genera datos operativos que nunca se analizan de forma sistemática. El sistema de facturación tiene patrones de estacionalidad que nadie grafica. El CRM tiene datos de conversión por canal que nadie cruza con costo de adquisición. El sistema de nómina tiene datos de rotación por departamento que nadie correlaciona con clima organizacional. Los datos existen; el análisis no.
La IA — y en muchos casos, la analítica descriptiva o predictiva convencional — puede convertir estos datos dormidos en información accionable. Un modelo de predicción de demanda basado en datos históricos de ventas permite ajustar inventarios y reducir quiebres de stock. Un análisis de patrones de rotación permite identificar factores de riesgo antes de que un empleado clave renuncie. Un modelo de segmentación de clientes permite personalizar la comunicación comercial sin requerir un equipo de marketing de 20 personas.
Agrawal, Gans y Goldfarb (2018), en “Prediction Machines,” reencuadraron la IA como tecnología de predicción: reduce el costo de generar predicciones. Para la empresa mediana, esto significa que análisis que antes requerían un equipo de ciencia de datos ahora pueden hacerse con herramientas de IA como servicio que se conectan a fuentes de datos existentes. El ROI no viene de la sofisticación del modelo sino de la decisión que se toma mejor con la información que el modelo produce.
El prerequisito aquí es doble: los datos deben existir (registrados, no en la cabeza de alguien) y deben tener un nivel mínimo de calidad (consistentes, sin duplicados masivos, con campos clave completos). Como exploraremos más adelante en este artículo, la IA sobre datos de mala calidad no produce análisis — produce alucinaciones con formato profesional.
Soporte interno con RAG (base de conocimiento consultable)
RAG (Retrieval-Augmented Generation) es una arquitectura que combina recuperación de información de documentos propios con generación de texto mediante un modelo de lenguaje. En términos prácticos: permite construir un asistente que responde preguntas basándose en la documentación interna de la organización — manuales de procedimientos, políticas, especificaciones técnicas, base de conocimiento de soporte.
Para una empresa de 200 personas, el caso de uso más inmediato es soporte interno: un empleado nuevo que necesita saber cómo procesar una devolución, un vendedor que necesita las especificaciones técnicas de un producto, un analista que necesita encontrar un procedimiento regulatorio. Sin RAG, la respuesta a estas preguntas depende de encontrar a la persona correcta, enviar un correo, esperar. Con RAG, la respuesta está disponible en segundos, basada en documentación oficial de la organización.
Los datos del sector sugieren que los empleados dedican hasta el 30% de su jornada a buscar información, y que casi la mitad de esas búsquedas no produce el resultado esperado. Organizaciones que implementan sistemas de base de conocimiento con RAG reportan ganancias de productividad del 30-50%, equivalentes a 45-75 minutos recuperados por empleado por día. El tiempo de implementación para un caso de uso focalizado es de 8 a 12 semanas.
El prerequisito es que la documentación exista. Si los procedimientos viven en la experiencia tácita de tres personas que llevan 15 años en la empresa y nunca se documentaron, no hay base de conocimiento que construir. RAG no inventa conocimiento; recupera y sintetiza el que ya existe en documentos. Este es un caso donde la IA funciona como catalizador de una práctica de gestión del conocimiento que debería existir con o sin tecnología. Para una exploración más profunda de esta arquitectura en contextos regulados, ver RAG en sectores regulados.
Clasificación inteligente de leads, tickets y documentos
Toda empresa mediana con volumen de interacciones enfrenta un problema de clasificación: el equipo comercial recibe leads que necesitan ser calificados y priorizados. El equipo de soporte recibe tickets que necesitan ser categorizados y dirigidos al área correcta. El equipo legal recibe documentos que necesitan ser clasificados por tipo, urgencia y relevancia. Estos procesos de clasificación son repetitivos, consumen tiempo de personal calificado, y son susceptibles de error humano cuando el volumen es alto.
Los modelos de clasificación basados en IA pueden automatizar esta tarea con niveles de precisión que igualan o superan la clasificación humana promedio. Un modelo de clasificación de leads puede asignar una probabilidad de conversión basada en datos históricos de leads anteriores, permitiendo al equipo comercial priorizar su tiempo en los leads con mayor potencial. Un modelo de clasificación de tickets puede categorizar por tema, urgencia y área responsable en milisegundos, reduciendo el tiempo de primera respuesta.
Lo relevante para la empresa mediana es que estos modelos no requieren entrenamiento desde cero. Las plataformas actuales permiten ajustar modelos pre-entrenados con datos propios mediante técnicas de fine-tuning ligero o simplemente mediante prompting con ejemplos. Una empresa con 5,000 tickets históricos etiquetados tiene datos suficientes para construir un clasificador que funcione con la precisión necesaria para uso operativo. El ROI se mide en tiempo liberado del personal calificado: si un analista dedica 3 horas diarias a clasificar manualmente y la IA reduce eso a 30 minutos de supervisión, las 2.5 horas liberadas se redirigen a trabajo de mayor valor.
Lo que no funciona (y por qué la mayoría de pilotos mueren)
Los datos sobre fracaso de pilotos de IA no son un secreto de la industria: IDC encontró que de cada 33 pruebas de concepto de IA que una empresa lanza, solo 4 llegan a producción. MIT reporta que el 95% de los pilotos de IA generativa no generan retorno medible. RAND Corporation documenta que más del 80% de los proyectos de IA fracasan. Estos números son consistentes entre fuentes independientes, lo cual sugiere que el problema es sistémico, no anecdótico. A continuación, los cuatro patrones de fracaso más frecuentes que observamos en la región.
Chatbots genéricos sin propósito definido. El caso de uso más implementado y más abandonado en empresas medianas es el chatbot de atención al cliente que no tiene acceso a los sistemas de la empresa, no entiende el contexto específico del negocio y responde con generalidades que el cliente podría encontrar en Google. El problema no es la tecnología del chatbot; es que se implementó sin definir qué problema específico debía resolver, sin alimentarlo con datos del negocio y sin integrarlo con los sistemas donde vive la información que el cliente necesita. Un chatbot que no puede consultar el estado de un pedido, verificar un saldo o generar una cotización específica no es un asistente — es un obstáculo entre el cliente y un humano que sí puede ayudar. Estos implementaciones no solo no generan valor; erosionan la confianza del cliente y de los empleados en la capacidad de la organización para adoptar tecnología.
IA sobre datos sucios o inexistentes. Ryseff, De Bruhl y Newberry (2024), en su investigación de RAND Corporation basada en entrevistas con 65 científicos de datos e ingenieros experimentados, identificaron que una de las cinco causas raíz de fracaso de proyectos de IA es que la organización carece de los datos necesarios para entrenar un modelo efectivo. En la práctica, esto se manifiesta de formas específicas: la empresa quiere predecir rotación pero no tiene datos históricos de salidas voluntarias clasificadas por motivo. Quiere automatizar clasificación de documentos pero sus documentos están en 14 formatos diferentes sin taxonomía consistente. Quiere personalizar la experiencia del cliente pero su CRM tiene el 40% de los registros duplicados y el 60% sin actualizar en más de un año. La IA no corrige la calidad de los datos; la amplifica. Si los datos son malos, las decisiones basadas en IA serán malas — pero con la apariencia de objetividad computacional que hace más difícil cuestionarlas.
Pilotos sin patrocinio ejecutivo. Un piloto de IA que nace en el departamento de TI sin patrocinio de un líder de negocio tiene una probabilidad alta de morir por inanición: no consigue los datos que necesita de otras áreas, no tiene presupuesto para escalar si funciona, no tiene un caso de negocio que justifique la inversión ante la junta directiva, y no tiene un dueño funcional que se haga responsable de que el resultado del modelo se traduzca en una decisión de negocio diferente. La investigación de MIT Sloan Management Review y BCG (2025) encontró que el 92% de los encuestados reporta que los desafíos culturales y de gestión del cambio son la barrera principal para convertirse en una organización impulsada por datos e IA. El patrocinio ejecutivo no es un nice-to-have; es el mecanismo que convierte un experimento técnico en una iniciativa de negocio con recursos, plazos y accountability.
Adopción forzada sin capacitación. Implementar una herramienta de IA y esperar que los empleados la adopten porque la gerencia lo decidió es repetir el error de cada ola tecnológica anterior. El ERP que nadie usaba correctamente porque no hubo capacitación adecuada. El CRM que los vendedores boicoteaban porque no entendían su valor. La herramienta de BI que generaba reportes que nadie leía. La IA tiene un agravante: la distancia cognitiva entre la herramienta y la experiencia previa del usuario es mayor. Un empleado puede intuir cómo funciona una hoja de cálculo por analogía con una hoja de papel. No puede intuir cómo funciona un modelo de lenguaje, qué puede y qué no puede hacer, cuándo confiar en su respuesta y cuándo verificarla. Sin capacitación específica — que incluya no solo el cómo sino el cuándo y el por qué — la adopción será superficial, errática o inexistente. Documentamos este problema con datos en Capacitación corporativa en IA.
El prerequisito que nadie menciona
Hay una conversación que debería preceder cualquier discusión sobre IA en una empresa mediana, y que rara vez ocurre: ¿están nuestros datos y procesos en condiciones de ser automatizados?
La IA opera sobre datos. Si los datos son inconsistentes, incompletos, duplicados o están dispersos en sistemas que no se comunican, la IA no resuelve estos problemas — los escala. Un modelo de predicción entrenado con datos de ventas donde el 30% de las transacciones no están registradas producirá predicciones que reflejan esa incompletitud. Un chatbot con RAG alimentado con documentos desactualizados responderá con información incorrecta, pero con la confianza lingüística que caracteriza a los modelos de lenguaje. Un clasificador entrenado con etiquetas inconsistentes — donde el mismo tipo de ticket fue categorizado de tres formas distintas según quien lo atendió — reproducirá esa inconsistencia.
Davenport y Ronanki (2018) identificaron tres categorías de aplicación de IA en su estudio de 152 proyectos: automatización de procesos, generación de insights a partir de datos, y engagement con clientes y empleados. Las tres requieren un sustrato de datos y procesos que muchas organizaciones no tienen. El proyecto de IA es, en la práctica, un revelador de deuda organizacional acumulada: procesos que nunca se documentaron, datos que nunca se gobernaron, decisiones que nunca se explicitaron.
Esto no significa que una empresa necesite perfección antes de empezar. Significa que necesita honestidad sobre su punto de partida. Un diagnóstico de 2 a 4 semanas que responda tres preguntas puede ahorrar meses de frustración:
| Pregunta diagnóstica | Qué evalúa | Señal de alerta |
|---|---|---|
| ¿Los datos necesarios para el caso de uso existen en formato digital y accesible? | Disponibilidad de datos | Datos en papel, en la cabeza de personas, o en sistemas sin API |
| ¿Esos datos son suficientemente consistentes y completos para que un modelo aprenda de ellos? | Calidad de datos | Duplicados masivos, campos vacíos >30%, taxonomías inconsistentes |
| ¿El proceso que se quiere mejorar está documentado y es suficientemente estable? | Madurez de proceso | Proceso diferente cada vez, dependiente de una sola persona, sin métricas actuales |
Si las tres respuestas son negativas, la inversión correcta no es en IA. Es en datos y procesos. La IA sobre caos produce caos más rápido. Y el caos con apariencia de inteligencia artificial es más peligroso que el caos reconocido como tal, porque reduce la probabilidad de que alguien lo cuestione. Para una guía práctica sobre qué arreglar en tus datos antes de pensar en IA, incluyendo un checklist de preparación y una secuencia de priorización, ver el artículo dedicado.
En Rizoma observamos un patrón recurrente: las organizaciones que obtienen valor real de la IA son las que ya tenían cierta disciplina en gestión de datos y procesos antes de que la IA llegara. No eran perfectas — ninguna lo es — pero tenían lo básico: procesos documentados aunque fueran mejorables, datos registrados aunque tuvieran inconsistencias corregibles, y al menos una persona con criterio técnico suficiente para evaluar lo que un proveedor promete versus lo que puede entregar. Estas condiciones no son glamorosas y no generan titulares en eventos de innovación, pero son las que determinan si la IA genera valor o genera decepción.
La evidencia es convergente: la madurez organizacional precede al valor de la IA. Sculley et al. (2015), en “Hidden Technical Debt in Machine Learning Systems,” documentaron que el código del modelo de ML representa una fracción mínima del sistema total en producción. El resto — recolección y validación de datos, infraestructura, monitoreo, gestión de configuración — es trabajo de ingeniería y de gestión que no tiene nada de glamoroso y todo de necesario. Para la empresa mediana, esto significa que el 80% del esfuerzo de un proyecto de IA exitoso no es IA — es preparación.
Hoja de ruta: 90 días para un primer caso de uso en producción
Lo que sigue no es un framework genérico. Es una secuencia probada en contextos de empresas medianas que equilibra rigor con velocidad. El objetivo es tener un caso de uso en producción — no en piloto, no en prueba de concepto, en producción — en 90 días. Esto requiere disciplina en la selección del caso de uso, honestidad sobre el estado de los datos, y compromiso ejecutivo sostenido.
Semanas 1-2: Identificar el caso de uso de mayor impacto y menor riesgo
El primer error que cometen la mayoría de las organizaciones es elegir el caso de uso más ambicioso. El segundo error es elegir el más fácil técnicamente pero irrelevante para el negocio. El criterio correcto es la intersección de impacto de negocio y viabilidad técnica. Para evaluar esto de forma estructurada:
| Criterio | Preguntas | Peso |
|---|---|---|
| Impacto de negocio | ¿Cuántas horas/semana consume este proceso? ¿Cuántas personas están involucradas? ¿Cuál es el costo del error actual? | Alto |
| Disponibilidad de datos | ¿Los datos necesarios existen? ¿En qué formato? ¿Con qué calidad? ¿Qué tan accesibles son? | Alto |
| Complejidad de integración | ¿Se necesita integrar con sistemas existentes? ¿Hay APIs disponibles? ¿Quién mantiene esos sistemas? | Medio |
| Patrocinio ejecutivo | ¿Hay un líder de negocio que patrocine este caso? ¿Tiene autoridad para cambiar el proceso actual? | Alto |
| Reversibilidad | ¿Se puede revertir si no funciona sin consecuencias graves? ¿Es un proceso interno o de cara al cliente? | Medio |
El resultado de estas dos semanas es un caso de uso seleccionado con criterios explícitos, un sponsor ejecutivo identificado, y una hipótesis clara: “Si automatizamos X con IA, esperamos una reducción de Y% en Z, medido por W.” La hipótesis es importante porque define el criterio de éxito antes de empezar — no después, cuando la inercia del proyecto crea incentivos para redefinir el éxito.
Semanas 3-4: Diagnóstico de datos y proceso
Con el caso de uso seleccionado, las siguientes dos semanas se dedican a evaluar la materia prima: los datos y el proceso. El diagnóstico de datos responde: ¿los datos existen, son accesibles, tienen la calidad mínima necesaria? El diagnóstico de proceso responde: ¿el proceso es suficientemente estable y documentado para que la automatización tenga sentido?
Este es el momento donde la mayoría de los proyectos de IA deberían detenerse y redirigirse — pero no lo hacen porque la inercia organizacional y el compromiso emocional con la tecnología ya están en movimiento. Si el diagnóstico revela que los datos necesitan limpieza significativa o que el proceso necesita rediseño, la decisión correcta es invertir las semanas 5-8 en remediación de datos o proceso en lugar de construir un prototipo sobre cimientos frágiles. Esto no es un retraso; es una inversión en que el prototipo funcione cuando se construya.
Mes 2: Prototipo con datos reales
El prototipo no es una demostración. Es una versión funcional del caso de uso que opera con datos reales — no datos de prueba, no datos inventados, datos reales de la organización. La diferencia es fundamental: un prototipo con datos de prueba demuestra que la tecnología funciona; un prototipo con datos reales demuestra que la tecnología funciona con los datos que la organización realmente tiene, con sus inconsistencias, sus excepciones y sus particularidades.
Durante este mes, el prototipo se construye y se itera. El equipo técnico — interno o externo — construye la primera versión. Los usuarios funcionales la prueban con casos reales. Se identifican las fallas, los bordes, las excepciones que el diseño inicial no contempló. Se ajusta. Se vuelve a probar. El objetivo no es la perfección — es un prototipo que funciona correctamente en el 80% de los casos y que tiene un plan documentado para el 20% restante.
Mes 3: Piloto controlado con métricas de éxito definidas
El piloto no es el prototipo con más usuarios. Es una operación controlada donde el caso de uso funciona en producción — con datos reales, usuarios reales, consecuencias reales — pero con tres mecanismos de control:
Primero, un grupo definido de usuarios que opera con la nueva herramienta mientras el resto mantiene el proceso anterior. Esto permite comparar rendimiento antes y después con un grupo de control implícito. Segundo, métricas de éxito definidas antes de empezar el piloto, no después. Si la hipótesis era “reducir el tiempo de clasificación de tickets en un 50%,” la métrica es tiempo promedio de clasificación, medido de la misma forma antes y durante el piloto. Tercero, criterios de decisión predefinidos: ¿qué resultado del piloto justifica escalar a toda la operación? ¿Qué resultado justifica iterar? ¿Qué resultado justifica detener?
Al final del mes 3, la organización tiene una de tres cosas: un caso de uso en producción con ROI medido, un caso de uso que necesita ajustes específicos con un plan para implementarlos, o la evidencia de que este caso de uso particular no genera el valor esperado — lo cual es información valiosa que evita meses de inversión adicional en la dirección equivocada.
Gobernanza mínima viable
El tema de gobernanza de IA genera una reacción predecible en empresas medianas: “eso es para empresas grandes.” La investigación del ILIA 2025 documenta que solo el 17% de las empresas en América Latina tiene marcos de gobernanza de IA. Pero la gobernanza no es un documento de 50 páginas ni un comité de 12 personas. Para una empresa mediana, la gobernanza mínima viable consiste en responder cinco preguntas antes de cada implementación de IA — y documentar las respuestas.
Pregunta 1: ¿Qué datos usa este sistema y quién es responsable de su calidad? Toda implementación de IA consume datos. Si nadie es responsable de la calidad de esos datos — su completitud, consistencia, actualización — el sistema degradará su rendimiento progresivamente sin que nadie lo note hasta que las consecuencias sean visibles. La respuesta a esta pregunta debe incluir un nombre propio, no un departamento.
Pregunta 2: ¿Qué pasa cuando el sistema produce un resultado incorrecto? Todos los modelos de IA producen resultados incorrectos en algún porcentaje de los casos. El tema no es eliminar el error — es definir qué ocurre cuando se produce. ¿Quién lo detecta? ¿Cómo se corrige? ¿Cómo se registra para mejorar el sistema? ¿Cuál es el impacto en el cliente o en el proceso si el error no se detecta a tiempo? Las respuestas a estas preguntas determinan si la implementación necesita supervisión humana permanente, muestreo periódico, o puede operar de forma autónoma.
Pregunta 3: ¿Qué datos personales o sensibles procesa y bajo qué base legal? Aun en ausencia de regulación específica de IA en la mayoría de los países centroamericanos, las leyes de protección de datos personales aplican. Si el sistema de IA procesa datos de clientes, empleados o proveedores, la organización debe poder responder bajo qué base legal lo hace, cómo protege esos datos, y qué derechos tienen los titulares. Esta no es una preocupación teórica: a medida que la regulación avanza — y la evidencia regional disponible sugiere que avanzará — las organizaciones que no pueden responder esta pregunta enfrentarán costos de remediación significativos. Para un análisis más detallado, ver Gobernanza de IA: el vacío que las organizaciones llenan mal.
Pregunta 4: ¿Cómo sabremos si el sistema deja de funcionar correctamente? Los modelos de IA degradan su rendimiento con el tiempo porque los datos del mundo real cambian — un fenómeno documentado como data drift (Gama et al., 2014). Un modelo de clasificación entrenado con datos de 2024 será menos preciso con datos de 2026 si el perfil de los clientes, los productos o las condiciones del mercado cambiaron. La respuesta a esta pregunta define qué métricas se monitorean, con qué frecuencia, y qué umbrales activan una revisión o reentrenamiento del modelo.
Pregunta 5: ¿Quién tiene la autoridad para desactivar el sistema? Si el sistema produce resultados incorrectos de forma sistemática, si se identifica un sesgo inaceptable, o si un cambio regulatorio lo hace no conforme, alguien debe tener la autoridad — y la información — para desactivarlo. En empresas medianas, esta pregunta frecuentemente no tiene respuesta porque nadie pensó que sería necesaria. Tenerla respondida antes de la implementación es la diferencia entre una respuesta ordenada y una crisis improvisada.
Estas cinco preguntas, documentadas y revisadas antes de cada implementación, constituyen un marco de gobernanza que es proporcional al tamaño y complejidad de una empresa mediana. No es exhaustivo. No cubre todos los escenarios posibles. Pero cubre los más frecuentes y más costosos. A medida que la organización madura en su uso de IA y el número de implementaciones crece, el marco puede expandirse — pero la base son estas cinco preguntas.
¿Qué distingue a los que logran resultados?
La investigación de RAND Corporation identificó cinco causas raíz de fracaso en proyectos de IA: malentendidos sobre el problema a resolver, falta de datos adecuados, priorizar tecnología sobre problemas reales, infraestructura insuficiente y aplicar IA a problemas demasiado difíciles para la tecnología actual. La inversión de estas causas define el perfil de las organizaciones que sí obtienen resultados.
Las organizaciones que logran resultados con IA en el rango de 50-500 personas comparten un patrón que no es tecnológico sino organizacional. Empiezan con un problema de negocio, no con una tecnología. Invierten en calidad de datos antes de invertir en modelos. Construyen capacidad interna — al menos una persona que entiende lo suficiente para evaluar proveedores y resultados — en lugar de delegar completamente en externos. Tienen un sponsor ejecutivo que entiende las posibilidades y las limitaciones. Y miden resultados con las mismas métricas que usarían para cualquier otra inversión operativa: tiempo ahorrado, errores reducidos, ingresos incrementales, costos evitados.
La evidencia de la OCDE (2025) respalda esto: el 91% de las pymes que usan IA generativa reportan ganancias de eficiencia, y el 76% citan mayor innovación. Pero estas son las pymes que ya la están usando — el sesgo de superviviente es real. Las que intentaron y abandonaron no aparecen en las estadísticas de beneficios. Lo que distingue a las que sobreviven es la calidad de la decisión inicial sobre qué automatizar, con qué datos, y bajo qué condiciones.
Davenport y Ronanki (2018) contrastaron el caso de un proyecto fallido en MD Anderson Cancer Center — un “moon shot” con IBM Watson que acumuló costos de 62 millones de dólares sin llegar a usarse con pacientes — con proyectos incrementales en la misma institución que lograron resultados concretos en satisfacción del paciente y eficiencia operativa. La lección se aplica directamente a empresas medianas: el proyecto de IA que fracasa no es el que no es lo suficientemente ambicioso; es el que es ambicioso sin las condiciones previas para sostener esa ambición.
No existe una solución genérica para la adopción de IA. Existe un proceso de evaluación, preparación e implementación que es específico a cada organización. Las organizaciones que respetan ese proceso obtienen resultados. Las que intentan saltarse pasos — porque el proveedor promete que su herramienta no requiere datos limpios, porque la competencia ya lo está haciendo, porque el CEO volvió de una conferencia entusiasmado — obtienen pilotos que mueren, presupuestos consumidos y escepticismo organizacional que dificulta los intentos futuros.
La brecha entre el 78% que considera la IA prioritaria y el 80% cuyos proyectos fracasan no se cierra con más tecnología. Se cierra con mejor criterio. Para la empresa mediana en Centroamérica, el momento de actuar es ahora — pero actuar con disciplina, no con prisa. El costo de no adoptar IA es real, pero el costo de adoptarla mal es mayor: consume presupuesto, erosiona confianza organizacional y retrasa la adopción que sí produciría valor. El artículo sobre automatización inteligente vs automatización ciega explora esta distinción con mayor profundidad.
La IA es una herramienta poderosa. Pero como toda herramienta poderosa, amplifica lo que encuentra: si encuentra disciplina, produce eficiencia; si encuentra desorden, produce desorden más rápido. La pregunta para el decisor de una empresa mediana no es “¿debemos usar IA?” — la respuesta a eso es sí, eventualmente. La pregunta es: “¿estamos listos para usarla bien, y si no, qué necesitamos hacer primero?”
Referencias
- Agrawal, A., Gans, J., & Goldfarb, A. (2018). Prediction Machines: The Simple Economics of Artificial Intelligence. Harvard Business Review Press.
- CEPAL & CENIA. (2025). Índice Latinoamericano de Inteligencia Artificial (ILIA 2025).
- Davenport, T. H., & Ronanki, R. (2018). Artificial intelligence for the real world. Harvard Business Review, 96(1), 108-116.
- Gama, J., Žliobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys, 46(4), 1-37.
- McKinsey & Company. (2024). The state of AI in early 2024: Gen AI adoption spikes and starts to generate value. McKinsey Global Survey.
- McKinsey & Company. (2025). The state of AI: How organizations are rewiring to capture value. McKinsey Global Survey.
- MIT Sloan Management Review & BCG. (2025). The emerging agentic enterprise: How leaders must navigate a new age of AI.
- OCDE. (2025). AI adoption by small and medium-sized enterprises. OECD Publishing.
- RAND Corporation. (2024). Ryseff, J., De Bruhl, B. F., & Newberry, S. J. The root causes of failure for artificial intelligence projects and how they can succeed. RAND Research Report RRA2680-1.
- Sculley, D., Holt, G., Golovin, D., et al. (2015). Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems, 28, 2503-2511.